
зүҮеңәж•°жҚ®з®ЎзҗҶжңҖйҮҚиҰҒзҡ„зӣ®ж Үд№ӢдёҖжҳҜдҝқжҢҒжӢҚж‘„иҝҮзЁӢдёӯи®°еҪ•е’ҢеҲӣе»әзҡ„жүҖжңүж•°жҚ®зҡ„е®Ңж•ҙжҖ§е’Ңе®Ңе…ЁжҖ§гҖӮз”ұдәҺиҝҷжҳҜжӮЁдҪңдёәж•°еӯ—еҪұеғҸе·ҘзЁӢеёҲжҲ–ж•°жҚ®з®ЎзҗҶе‘ҳзҡ„иҙЈд»»пјҢеӣ жӯӨзҶҹжӮүдёҖдәӣж ёеҝғжҰӮеҝөжҳҜйқһеёёжңүз”Ёзҡ„гҖӮ
жң¬ж–ҮжҳҜдёӨйғЁеҲҶзі»еҲ—ж–Үз« дёӯзҡ„第дёҖзҜҮпјҢд»Ӣз»ҚдәҶж•°жҚ®з®ЎзҗҶжҠҖжңҜж–№йқўзҡ„еҹәжң¬зҹҘиҜҶгҖӮжҲ‘们е°Ҷж·ұе…ҘжҺўи®Ёж•°жҚ®е®Ңж•ҙжҖ§зҡ„еҗ«д№үгҖҒеҸҜиғҪеЁҒиғҒж•°жҚ®е®Ңж•ҙжҖ§зҡ„дёҖдәӣжҪңеңЁй—®йўҳпјҢд»ҘеҸҠж ЎйӘҢе’ҢдёҺе“ҲеёҢз®—жі•еҰӮдҪ•её®еҠ©жҲ‘们дҝқжҠӨж•°жҚ®е®Ңж•ҙжҖ§гҖӮ
еңЁеҗҺз»ӯзҡ„ж–Үз« дёӯпјҢжҲ‘们е°Ҷи®Ёи®әжё…еҚ•ж–Ү件д»ҘеҸҠеҰӮдҪ•дҪҝз”Ёжё…еҚ•ж–Ү件жқҘдҝқжҢҒж•°жҚ®зҡ„е®Ңе…ЁжҖ§пјҢд»ҺиҖҢиҪ¬еҗ‘жҲҗеҠҹж•°жҚ®з®ЎзҗҶзҡ„第дәҢдёӘж”ҜжҹұгҖӮдҪҶйҰ–е…ҲпјҢжҲ‘们иҝҳжҳҜиҰҒи°Ҳи°Ҳж•°жҚ®е®Ңж•ҙжҖ§пјҒ
ж•°жҚ®е®Ңж•ҙжҖ§
дҝқжҢҒе®Ңж•ҙжҖ§пјҲжҲ– “ж•°жҚ®е®Ңж•ҙжҖ§”пјүжҳҜжҢҮзЎ®дҝқж•°жҚ®еңЁж•ҙдёӘз”ҹе‘Ҫе‘ЁжңҹеҶ…йғҪжҳҜ “жӯЈзЎ® “зҡ„гҖӮеҜ№дәҺе·ІеҪ•еҲ¶зҡ„еӘ’дҪ“ж–Ү件пјҢиҝҷж„Ҹе‘ізқҖж–Ү件жңӘиў«ж— ж„Ҹжӣҙж”№пјҢжүҖеҢ…еҗ«зҡ„еҶ…е®№дёҺж‘„еҪұжңәеҪ•еҲ¶ж—¶зӣёеҗҢгҖӮ
зҗҶи®әдёҠеҗ¬иө·жқҘеҫҲз®ҖеҚ•пјҢдҪҶе®һйҷ…ж“ҚдҪңиө·жқҘеҚҙеҫҲжЈҳжүӢгҖӮиҜ•жғідёҖдёӢпјҢе°Ҷж–Ү件д»Һж‘„еҪұжңәж•°жҚ®еҚЎдј иҫ“еҲ°еӨ–зҪ®зЎ¬зӣҳж—¶пјҢйңҖиҰҒдёҖй•ҝ串硬件е’ҢиҪҜ件组件еҚҸеҗҢе·ҘдҪңпјҡВ
- йҖҡиҝҮеҸҜжҸ’жӢ”з”өзјҶиҝһжҺҘзҡ„еҗ„з§ҚдёҚеҗҢзҡ„и®ҫеӨҮпјҢ
- иҜ»еҚЎеҷЁиҮӘеёҰжҺ§еҲ¶еҷЁе’ҢиҝһжҺҘеҷЁпјҢ
- еӣәжҖҒзЎ¬зӣҳжҲ–зЈҒзӣҳжҺ§еҲ¶еҷЁз»„件е’Ңзј“еӯҳпјҢ
- USB жҲ– Thunderbolt жҺҘеҸЈз»„件пјҢ
- RAID йҳөеҲ—зі»з»ҹпјҲ硬件жҲ–иҪҜ件йҳөеҲ—пјүпјҢ
- еӨҡдёӘж–Ү件系з»ҹпјҲеҸҜиғҪжҳҜдёҚеҗҢзұ»еһӢзҡ„пјүпјҢжңүж—¶жҳҜиҷҡжӢҹж–Ү件系з»ҹпјҲеҰӮ Codex VFSпјүпјҢеңЁйңҖиҰҒж—¶дёәзЈҒзӣҳеҚ·еҲӣе»әж–Ү件数жҚ®пјҢ
- дёҖдёӘж“ҚдҪңзі»з»ҹпјҢеёҰжңүз”ЁдәҺиҜ»еҶҷж–Ү件зҡ„ж–Ү件и®ҝй—®дҫӢзЁӢгҖҒи®ҝй—®жқғйҷҗз®ЎзҗҶзі»з»ҹгҖҒRAM дёӯзҡ„ж–Ү件缓еӯҳжңәеҲ¶гҖҒеӨҡзәҝзЁӢж”ҜжҢҒпјҢ
- д»ҘеҸҠжү§иЎҢж•°жҚ®дј иҫ“зҡ„иҪҜ件еә”з”ЁзЁӢеәҸпјҢеҰӮ Pomfort Silverstack жҲ– Offload ManagerгҖӮ
еҘҪж¶ҲжҒҜжҳҜпјҡж–Ү件еҸ‘з”ҹж„ҸеӨ–жӣҙж”№зҡ„жғ…еҶө并дёҚеёёи§ҒгҖӮдёҚиҝҮпјҢиҝҷд№ҹ并йқһдёҚеҸҜиғҪгҖӮзү©зҗҶе’ҢдәӨдә’ејҸ组件зҡ„ж•°йҮҸгҖҒзү©зҗҶиҝһжҺҘеҷЁе’Ңз”өзјҶиҝһжҺҘгҖҒзӢ¬з«Ӣз”өжәҗд»ҘеҸҠдёҚеҗҢдҫӣеә”е•Ҷзҡ„еӣә件е’ҢиҪҜ件зүҲжң¬пјҢйғҪдјҡеңЁжҹҗдәӣжғ…еҶөдёӢеўһеҠ еҮәй”ҷзҡ„еҮ зҺҮгҖӮйӮЈд№ҲпјҢжҪңеңЁзҡ„еҗҺжһңжҳҜд»Җд№Ҳе‘ўпјҹи®©жҲ‘们жқҘзңӢеҮ дёӘеңЁж–Үд»¶дј иҫ“жҲ–еӯҳеӮЁиҝҮзЁӢдёӯеҸҜиғҪеҮәзҺ°й—®йўҳзҡ„дҫӢеӯҗпјҡВ
з©әж–Ү件пјҡВ еӨҚеҲ¶иҝҮзЁӢдёӯеҸҜиғҪдјҡеҮәзҺ°иҝҷз§Қжғ…еҶөпјҢеҚіж–Ү件已еҲӣе»әпјҢдҪҶжңӘжҲҗеҠҹеҶҷе…Ҙе…¶еҶ…е®№гҖӮеҸҜиғҪзҡ„еҺҹеӣ д»ӢиҙЁе·Іж»ЎгҖҒи®ҝй—®жқғйҷҗдёҚи¶іжҲ–еҲӣе»әж–Ү件еҗҺиҝӣзЁӢдёӯжӯўгҖӮ
ж–Ү件缩зҹӯпјҡВ еңЁеӨҚеҲ¶иҝҮзЁӢдёӯпјҢз”ұдәҺеҶҷе…ҘиҝҮзЁӢдёҚе®Ңж•ҙпјҢеҸҜиғҪдјҡеҮәзҺ°иҝҷз§Қжғ…еҶөгҖӮеҸҜиғҪзҡ„еҺҹеӣ пјҡеӨҚеҲ¶дёӯжӯўгҖҒд»ӢиҙЁе·Іж»ЎгҖҒз”өжәҗжҲ–иҝһжҺҘж•…йҡңд»ҘеҸҠжңӘжҒўеӨҚиҝӣзЁӢгҖӮ
ж–Ү件еҶ…е®№й”ҷиҜҜпјҡеҸҜиғҪзҡ„еҺҹеӣ жңүеҫҲеӨҡпјҡ иҝҷеҸҜиғҪеҸ‘з”ҹеңЁж•°жҚ®еқ—еңЁеҶҷе…ҘиҝҮзЁӢдёӯеҮәзҺ°ж··д№ұпјҢдҫӢеҰӮпјҢеӨҡзәҝзЁӢзҡ„й—®йўҳжҲ–й”ҷиҜҜгҖӮж•°жҚ®еқ—еңЁеҚ·дёҠеҲҶй…ҚдҪҶжңӘеҶҷе…Ҙж—¶д№ҹеҸҜиғҪеҸ‘з”ҹиҝҷз§Қжғ…еҶөгҖӮиҝҷж ·пјҢж јејҸеҢ–еӯҳеӮЁеҚЎеүҚеҶҷе…Ҙзҡ„ж—§еҶ…е®№е°ұдјҡ “й—ӘзҺ° “еҮәжқҘпјҢжҳҫзӨәдёәй”ҷиҜҜзҡ„еҶ…е®№гҖӮеҸҰдёҖз§ҚеҸҜиғҪзҡ„жғ…еҶөжҳҜеңЁдј иҫ“жҲ–еӯҳеӮЁиҝҮзЁӢдёӯеҮәзҺ°жҜ”зү№й”ҷиҜҜпјҢдҫӢеҰӮпјҢ组件жҲ–еӯҳеӮЁ/еҶ…еӯҳеҮәзҺ°ж•…йҡңжҲ–дёҚеҸҜйқ гҖӮж–Ү件еҶ…е®№д№ҹеҸҜиғҪе®Ңе…Ёй”ҷиҜҜжҲ–жҚҹеқҸпјҢдҫӢеҰӮж–Ү件系з»ҹз»“жһ„жҚҹеқҸгҖӮ
йҖҡиҝҮзј–иҫ‘дҝ®ж”№ж–Ү件пјҡж–Ү件д№ҹеҸҜиғҪиў«зј–иҫ‘ж”№еҸҳпјҢдҫӢеҰӮпјҢиҪҜ件еә”з”ЁзЁӢеәҸеңЁжү“ејҖж–Ү件时иҰҶзӣ–дәҶж•ҙдёӘж–Ү件жҲ–йғЁеҲҶж–Ү件пјҢиҖҢз”ЁжҲ·еҸҜиғҪж— ж„Ҹдёӯж“ҚдҪңжҲ–иҖ…жңӘеҜҹи§үеҲ°иҝҷз§Қж“ҚдҪңгҖӮ
еҰӮдҪ•е®һзҺ°ж•°жҚ®е®Ңж•ҙжҖ§В
еҘҪдәҶпјҢжҒҗжҖ–еңәжҷҜе°ұи®ІеҲ°иҝҷйҮҢгҖӮжӮЁзҺ°еңЁеҸҜиғҪдјҡй—®иҮӘе·ұпјҢиҜҘеҰӮдҪ•её®еҠ©з»ҙжҠӨж•°жҚ®е®Ңж•ҙжҖ§гҖӮдёӢйқўпјҢжҲ‘们е°Ҷеҗ‘дҪ д»Ӣз»ҚдёҖдёӘжңүеҠ©дәҺжЈҖжөӢдёҠиҝ°й—®йўҳзҡ„ж ёеҝғжҰӮеҝөпјҡ и®Ўз®—е’ҢйӘҢиҜҒеҚ•дёӘж–Ү件зҡ„ж ЎйӘҢе’ҢгҖӮ
йҰ–е…ҲпјҢи®©жҲ‘们жқҘдәҶи§ЈдёҖдёӢд»Җд№ҲжҳҜж ЎйӘҢе’ҢгҖҒеҰӮдҪ•дҪҝз”Ёе“ҲеёҢз®—жі•жқҘеҲӣе»әж ЎйӘҢе’ҢпјҢд»ҘеҸҠеҰӮдҪ•дҪҝз”Ёе®ғ们жқҘжЈҖжҹҘж–Ү件еҶ…е®№зҡ„е®Ңж•ҙжҖ§гҖӮ
дёәдәҶжЈҖжөӢж–Ү件еңЁдј иҫ“жҲ–еӯҳеӮЁиҝҮзЁӢдёӯзҡ„й”ҷиҜҜпјҢйҖҡеёёдјҡеҲӣе»әж ЎйӘҢе’ҢгҖӮе…¶еҺҹзҗҶжҳҜдҪҝз”ЁдёҖз§Қз®—жі•пјҲж ЎйӘҢе’ҢеҮҪж•°пјүпјҢд»Һд»»ж„ҸеӨ§е°Ҹзҡ„ж•°жҚ®еқ—пјҲдҫӢеҰӮпјҢж–Ү件пјүдёӯеҲӣе»әдёҖе°Ҹж®өж•°жҚ®пјҲж ЎйӘҢе’ҢпјүгҖӮдёҖдёӘеҘҪзҡ„ж ЎйӘҢе’ҢеҮҪж•°жңүдёҖдёӘйқһеёёпјҲйқһеёёйқһеёёпјүй«ҳзҡ„жҰӮзҺҮпјҢеҚіеҪ“ж–Ү件еҶ…е®№зҡ„д»»дҪ•йғЁеҲҶеҸ‘з”ҹеҸҳеҢ–ж—¶пјҢз»ҷе®ҡж–Ү件зҡ„ж ЎйӘҢе’ҢдјҡеҸҳеҫ—дёҚдёҖж ·гҖӮж ЎйӘҢе’ҢеҮҪж•°д№ҹжҳҜзЎ®е®ҡзҡ„пјҢеӣ жӯӨеҸҜд»ҘйҡҸж—¶йҮҚж–°и®Ўз®—ж ЎйӘҢе’ҢгҖӮ
жҚўеҸҘиҜқиҜҙпјҡ
еңЁдј иҫ“жҲ–еӨҚеҲ¶ж–Ү件еҗҺпјҢи®Ўз®—ж–Ү件зҡ„ж ЎйӘҢе’ҢпјҢе°Ҷи®Ўз®—еҮәзҡ„ж ЎйӘҢе’ҢдёҺд№ӢеүҚдёәиҜҘж–Ү件计算еҮәзҡ„ж ЎйӘҢе’ҢпјҲеҰӮеңЁжәҗзЎ¬зӣҳеҚ·дёҠпјүиҝӣиЎҢжҜ”иҫғпјҢе°ұиғҪд»ҘйқһеёёпјҲйқһеёёйқһеёёпјүй«ҳзҡ„жҰӮзҺҮзЎ®дҝқж–Ү件еҶ…е®№дҝқжҢҒдёҚеҸҳгҖӮеҰӮжһңж ЎйӘҢе’ҢдёҚзӣёзӯүпјҢеҲҷеҸҜд»ҘиӮҜе®ҡеҶ…е®№еҸ‘з”ҹдәҶеҸҳеҢ–гҖӮеҰӮжһңж ЎйӘҢе’ҢзӣёзӯүпјҢеҲҷеҸҜд»Ҙи®Өдёәж–Ү件жңӘиў«дҝ®ж”№гҖӮ
иҝҷжҳҜеңЁиҪҜ件дёӯдҪҝз”Ёж ЎйӘҢе’ҢжқҘжЈҖжөӢж–Ү件жӣҙж”№пјҢе’Ңе®һж–Ҫзҡ„жүҖжңүж–Ү件зҡ„е®Ңж•ҙжҖ§жЈҖжҹҘзҡ„еҹәжң¬еҺҹзҗҶгҖӮ
ж ЎйӘҢе’Ңж–№жі•з§Қзұ»з№ҒеӨҡпјҢжңүдәӣйҖӮз”ЁдәҺеҫҲе°Ҹзҡ„ж•°жҚ®еқ—пјҢжңүдәӣз”ҡиҮіз”ЁдәҺзә й”ҷгҖӮдҪҶжңҖйҖӮеҗҲе’ҢжңҖеёёз”Ёзҡ„пјҢзЎ®дҝқж–Ү件数жҚ®е®Ңж•ҙжҖ§зҡ„ж ЎйӘҢе’ҢеҮҪж•°жҳҜhashпјҲе“ҲеёҢпјүз®—жі•гҖӮ
HASH пјҲе“ҲеёҢпјүз®—жі•
hashпјҲе“ҲеёҢпјүеҮҪж•°е°Ҷд»»ж„ҸеӨ§е°Ҹзҡ„ж•°жҚ®еқ—пјҲеҚіж–Ү件еҶ…е®№пјүжҳ е°„дёәдёҖдёӘзҹӯзҡ„пјҲеӣәе®ҡзҡ„пјүеӨ§е°ҸеҖјгҖӮиҝҷжӯЈжҳҜжҲ‘们еҜ№ж ЎйӘҢе’ҢеҮҪж•°зҡ„иҰҒжұӮгҖӮhash еҮҪж•°еҲӣе»әзҡ„еҖјз§°дёә “е“ҲеёҢеҖј”гҖӮз”ЁдәҺеҲӣе»әе“ҲеёҢеҖјзҡ„е“ҲеёҢз®—жі•еҗҚз§°жңүж—¶д№ҹз§°дёә “е“ҲеёҢзұ»еһӢ”пјҲдҫӢеҰӮпјҢдёҖдёӘж–Ү件зҡ„е“ҲеёҢеҖјеҸҜиғҪжҳҜ MD5 зұ»еһӢзҡ„ f5b96775f6c2d310d585bfa0d2ff633cпјүгҖӮ
ж №жҚ®з»ҙеҹәзҷҫ科пјҢ”дёҖдёӘеҘҪзҡ„е“ҲеёҢеҮҪж•°иҰҒж»Ўи¶ідёӨдёӘеҹәжң¬зү№жҖ§пјҡ 1) и®Ўз®—йҖҹеәҰиҰҒйқһеёёеҝ«пјӣ2) е°ҪйҮҸеҮҸе°‘иҫ“еҮәеҖјзҡ„йҮҚеӨҚпјҲзў°ж’һпјү”гҖӮ
еҪ“дёӨдёӘдёҚеҗҢзҡ„ж•°жҚ®ж–Ү件дә§з”ҹзӣёеҗҢзҡ„е“ҲеёҢеҖјж—¶пјҢе°ұдјҡеҸ‘з”ҹ “зў°ж’һ”гҖӮ еҸ‘з”ҹиҝҷз§Қжғ…еҶөзҡ„жҰӮзҺҮеә”е°ҪеҸҜиғҪе°ҸгҖӮзӣёеҸҚпјҢиҫ“еҮәиҢғеӣҙеҶ…зҡ„жҜҸдёӘе“ҲеёҢеҖјйғҪеә”д»ҘеӨ§иҮҙзӣёеҗҢзҡ„жҰӮзҺҮз”ҹжҲҗгҖӮиҝҷж ·пјҢе“ҲеёҢз®—жі•е°ұиғҪеҫҲеҘҪең°е®һзҺ°жҲ‘们зҡ„зӣ®зҡ„ – еҪ“з»ҷе®ҡзҡ„ж•°жҚ®дёҚеҗҢж—¶пјҢе®ғе°ұдјҡдә§з”ҹдёҚеҗҢзҡ„е“ҲеёҢеҖјгҖӮ
д»ҘдёӢжҳҜеӘ’дҪ“з®ЎзҗҶжөҒзЁӢдёӯйҖҡеёёдҪҝз”Ёзҡ„е“ҲеёҢз®—жі•зҡ„еҮ дёӘзӨәдҫӢпјҢ并йҷ„жңүзӨәдҫӢеҖјпјҡ
- MD5В (128 bit, зӨәдҫӢеҖј:В
f5b96775f6c2d310d585bfa0d2ff633c) - xxhash64В (64 bit, зӨәдҫӢеҖј:В
f409b64875d02fa1) - C4В (512 bit, зӨәдҫӢеҖј:В
c45TH1egbyWxtjgFmisoPypYXcizxPbywFzkbhevak2NgQr3HND5j99HR8UQDwT8pQoS8k3yxhLRGJPoNgR1zUin31)
зў°ж’һжҰӮзҺҮ
и®©жҲ‘们иҖғиҷ‘дёҖз§ҚиғҪдә§з”ҹе®Ңе…ЁеқҮеҢҖеҲҶеёғеҖјзҡ„е“ҲеёҢз®—жі•гҖӮйӮЈд№ҲпјҢеҪ“дёӨж¬ЎжҹҘзңӢдёҖдёӘж–Ү件时еҸ‘з”ҹзў°ж’һзҡ„еҮ зҺҮпјҲеҚідҝ®ж”№еҗҺзҡ„ж–Ү件дјҡдә§з”ҹзӣёеҗҢзҡ„е“ҲеёҢеҖјпјүеҸҜд»Ҙз”ұе“ҲеёҢеҖјзҡ„й•ҝеәҰеҶіе®ҡпјҢеҰӮдёӢжүҖзӨәпјҡ
зў°ж’һжҰӮзҺҮпјҲеҚізҗҶжғізҡ„е“ҲеёҢз®—жі•еҜ№дёӨдёӘдёҚеҗҢж–Ү件еҶ…е®№дә§з”ҹзӣёеҗҢе“ҲеёҢеҖјзҡ„жҰӮзҺҮпјүдёә е…¶дёӯпјҢl жҳҜе“ҲеёҢй•ҝеәҰпјҲжҜ”зү№пјүгҖӮ
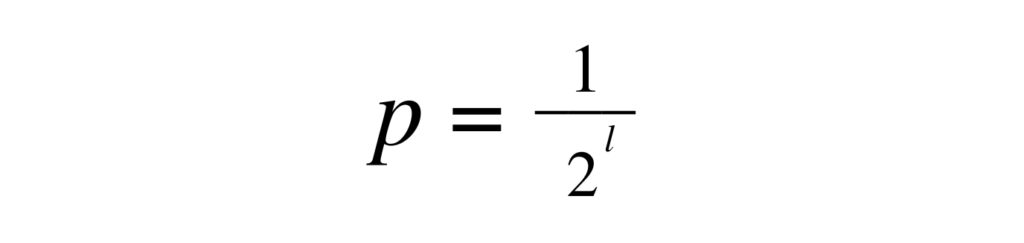
еӣ жӯӨпјҢеҜ№дәҺе“ҲеёҢеҖјй•ҝеәҰдёә 64 дҪҚзҡ„е“ҲеёҢз®—жі•пјҲдҫӢеҰӮ xxhash64пјүпјҢиҜҘжҰӮзҺҮдёә 1 / 2^ 64пјҢзәҰдёә 1/18.446.744.073.709.551.616 жҲ– 5.42101086 Г— 10^ -20гҖӮжҚўеҸҘиҜқиҜҙпјҢжӮЁйңҖиҰҒе°қиҜ•еҜ№еҗҢдёҖж–Ү件иҝӣиЎҢзәҰ 185.395.973.344.368.338пјҲ185 quadrillionпјүж¬ЎйҡҸжңәжӣҙж”№пјҢзӣҙеҲ°жүҖжңүжҜ”иҫғзҡ„жҖ»дҪ“зў°ж’һжҰӮзҺҮи¶…иҝҮ 1%гҖӮд№ҹе°ұжҳҜиҜҙпјҢжҜҸз§’е°қиҜ• 1000 ж¬Ўз»ҷе®ҡж–Ү件зҡ„жӣҙж”№пјҢйңҖиҰҒ 5.878.867пјҲ590 дёҮпјүе№ҙзҡ„ж—¶й—ҙпјҢиҖҢ 99% зҡ„жҰӮзҺҮд»ҚдёҚдјҡеҸ‘з”ҹзў°ж’һгҖӮ
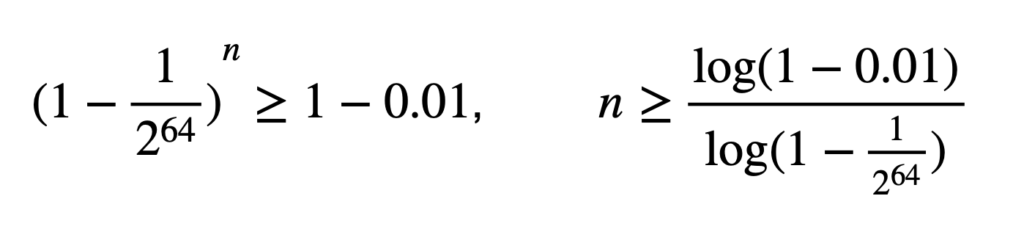
еҚідҪҝе“ҲеёҢ算法并дёҚиғҪе®Ңе…ЁеқҮеҢҖең°еҲҶй…ҚеҖјпјҢдҪҶеҸҜд»ҘжғіиұЎпјҢ64 дҪҚеҜ№дәҺе“ҲеёҢеҖјжқҘиҜҙе·Із»ҸжҳҜеҫҲеҘҪзҡ„еӨ§е°ҸдәҶпјҢеҸҜд»ҘжЈҖжөӢж–Ү件дёӯзҡ„д»»ж„ҸеҸҳеҢ–гҖӮ
йҖҹеәҰ
е“ҲеёҢз®—жі•еҸҜиғҪжҲҗдёәж•°жҚ®дј иҫ“ж—¶зҡ„йҷҗеҲ¶еӣ зҙ пјҢеӣ дёәжҲ‘们жҖ»жҳҜеёҢжңӣеңЁдј иҫ“иҝҮзЁӢдёӯеҲӣе»әе“ҲеёҢеҖјгҖӮеӣ жӯӨпјҢйҷӨдәҶдј иҫ“е®һйҷ…ж•°жҚ®еӨ–пјҢиҝҳйңҖиҰҒи®Ўз®—иҝҷдәӣж•°жҚ®зҡ„е“ҲеёҢеҖј вҖ“ иҝҷеҪ“然йңҖиҰҒйўқеӨ–зҡ„ CPU ж—¶й—ҙгҖӮxxhash зі»еҲ—е“ҲеёҢз®—жі•зҡ„зҪ‘з«ҷжҸҗдҫӣдәҶдёҚеҗҢе“ҲеёҢз®—жі•зҡ„йҖҹеәҰжҰӮи§ҲгҖӮ
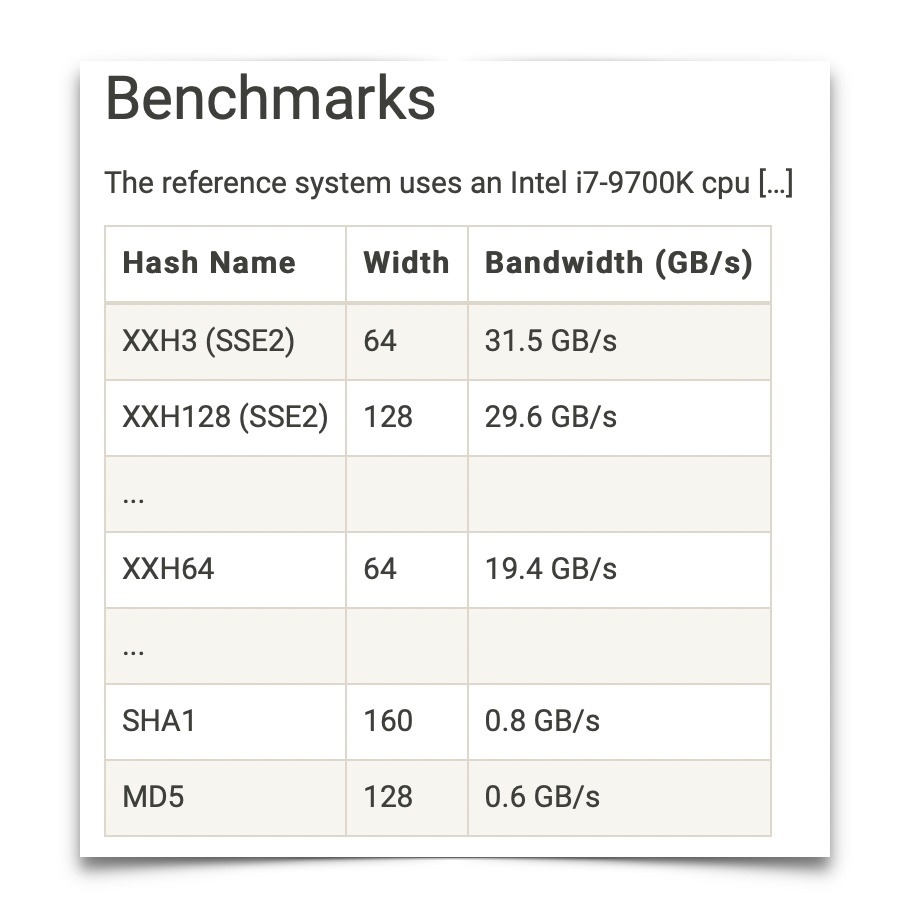
第дёҖдёӘеҗҜзӨәжҳҜпјҢй•ҝеәҰпјҲеҚіе“ҲеёҢеҖјзҡ„дҪҚж•°пјү并дёҚдёҖе®ҡдёҺз®—жі•зҡ„йҖҹеәҰзӣёеҜ№еә”гҖӮеҸҰдёҖдёӘеҗҜзӨәжҳҜпјҢжңҖеӨ§йҖҹеәҰзҡ„е·®ејӮеҸҜиғҪеҫҲеӨ§пјҲдҫӢеҰӮпјҢеңЁзӣёеҗҢзҡ„и®Ўз®—жңә硬件дёҠпјҢXXH3 е’Ң MD5 д№Ӣй—ҙзҡ„е·®ејӮеҸҜиҫҫзәҰ 50 еҖҚпјүгҖӮиҝҷжҳҜеӣ дёәе“ҲеёҢеҖјйңҖиҰҒдёҖдёӘеӯ—иҠӮдёҖдёӘеӯ—иҠӮең°жҢүйЎәеәҸи®Ўз®—пјҢдёҚе®№жҳ“е®һзҺ°еӨҡзәҝзЁӢгҖӮиҝҷж„Ҹе‘ізқҖпјҢдёҖдёӘ CPU еҶ…ж ёзҡ„йҖҹеәҰйҷҗеҲ¶дәҶе“ҲеёҢеҖјзҡ„и®Ўз®—иҝҮзЁӢпјҢиҖҢе°ҶдёҖдёӘе“ҲеёҢеҖји®Ўз®—иҝҮзЁӢеҲҮжҚўеҲ°е…·жңүжӣҙеӨҡеҶ…ж ёзҡ„ CPU дёҚдјҡдҪҝе“ҲеёҢеҖји®Ўз®—жӣҙеҝ«пјҲеҪ“然пјҢжӮЁзҡ„иҪҜ件еҸҜиғҪдјҡеҗҢж—¶еҜ№еӨҡдёӘж–Ү件иҝӣиЎҢзӢ¬з«Ӣе“ҲеёҢд»ҘжҸҗй«ҳж•ҙдҪ“еҗһеҗҗйҮҸпјүгҖӮ
з»“и®әдёҺеұ•жңӣ
еңЁжң¬ж–ҮдёӯпјҢжҲ‘们讨и®әдәҶеҲӣе»әж ЎйӘҢе’Ңе°ҶеҰӮдҪ•жңүеҠ©дәҺжЈҖжөӢж•°жҚ®зҡ„е®Ңж•ҙжҖ§зҡ„й—®йўҳгҖӮжҲ‘们讨и®әдәҶе“ҲеёҢз®—жі•зҡ„дҪҝз”Ёе’Ңе“ҲеёҢеҖјдҪңдёәж ЎйӘҢе’Ңзҡ„дҪҝз”ЁпјҢ并еұ•зӨәдәҶиҪҜ件еә”з”ЁзЁӢеәҸжҳҜеҰӮдҪ•еҸ‘зҺ°ж•°жҚ®еңЁе…¶з”ҹе‘Ҫе‘ЁжңҹеҶ…жҳҜеҗҰеҸ‘з”ҹдәҶеҸҳеҢ–пјҢ并еҗ‘з”ЁжҲ·еҸ‘еҮәзӣёеә”зҡ„иӯҰе‘ҠгҖӮ
еңЁжҺҘдёӢжқҘзҡ„ж–Үз« дёӯпјҢжҲ‘们е°ҶжҺўи®Ёе®Ңе…ЁжҖ§зҡ„й—®йўҳпјҢд»ҘеҸҠеңЁж•°жҚ®з®ЎзҗҶжөҒзЁӢдёӯйҮҮеҸ–е“ӘдәӣжҺӘж–ҪжқҘзЎ®дҝқжІЎжңүж–Ү件被йҒ—еҝҳгҖӮ敬иҜ·е…іжіЁжң¬зі»еҲ—ж–Үз« зҡ„第дәҢйғЁеҲҶпјҒ



